
克萊爾•蔡等人在2008年的研究再次表明,在達到最低界限之後,更多的信息只能意味着多餘的信息和恆定的準確度。他們對美式足球球迷就15場大學生聯賽的結果和比分預測情況進行了檢驗。信息(完全由不參與試驗的球迷選擇)以隨機方式分五輪顯示。每一輪顯示6條信息(稱爲“提示”)。
在提供的信息中,故意刪去了球隊名稱,以剔除由此帶來的誤導作用。這些資料包含了諸如本方失球、反攻次數以及推進距離等統計數據。
試驗的參與者是來自芝加哥大學的30位本科生和研究生。參與者平均花費一個小時左右的時間完成實驗,他們的酬勞是15美元的固定收入。此外,實驗人員還承諾,表現最佳者還將獲得額外50美元的獎勵。爲參與本次研究,參與者必須通過測試顯示他們對大學生足球聯賽有足夠的瞭解。
爲了從根本上說明更多信息是否就意味更好的信息,他們對比賽預測情況採用了實際測試中未曾使用的迴歸分析。雖然這聽起來有點深奧複雜,但其真正的含義不過是說:每一輪均爲計算機模型提供新的信息。這就模擬出試驗的真正參與者(人)所面對的環境。
實驗結果如圖19-1所示。在僅有第一輪信息的情況下(6條提示),計算機模型的預測準確度約爲56%,隨着信息量的逐步增加,到全部信息提供完畢,預測的準確度也上升到71%。
可以說,從統計模擬的角度看,更多的信息確實意味着更好的信息。但是,對於人(而不是計算機)來說,試驗卻得出了一個完全不同的結果。在提供的信息量達到全部信息量的62%之後,預測準確度幾乎不再變化。在最初幾輪,參與者的預測準確度高於計算機模型,只不過在統計上不具有顯著性,但是在最後幾輪中卻不及計算機模型。
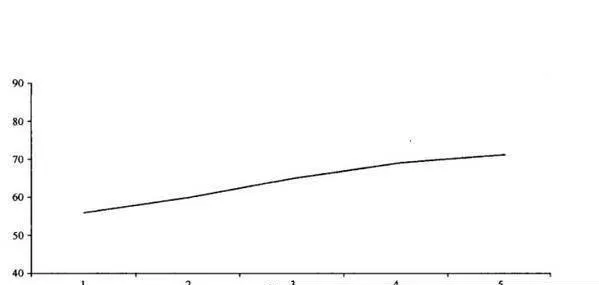
圖19-1 計算機模型的預測準確度(%)
不過,試驗參與者的信心往往會隨着信息的增加而大增。在最初提供6條信息的情況下,參與者的信心度爲69%,到信息量達到30條時,信心度已經激增至接近80%。因此,幾乎和斯洛維奇最早的研究完全一致,信息量增加帶來的只有信心,而不是準確度。
這一結論反映出人類思維所受到的認知約束。早在1956年的時候,喬治•米勒就曾發現,一般人的存儲能力(如果您喜歡,不妨稱之爲“大腦的便籤”)只能同時處理7個字節的信息(正負誤差爲2個)。
歸根結底,人類永遠不可能成爲能力無限的超級計算機。因此,我們沒有道理去挑戰自己的認知極限,而是應該去探索發掘我們天生的察賦。所以說,我們根本不必去收集無窮無盡的信息,倒是應該用更多時間去剖析和掌握真正有價值的東西。