
多層推進分析進分析通過先優化策略參數,然後將量化交易策略置於其後的數據進行檢驗的方法,可以較爲有效地對策略所具有的過度擬合問題進行判斷。但是值得注意的是,在進行推進分析的過程中,研究人員有時仍然會將一些參數固定從而方便研究。用第4章提到的自迴歸策略舉例面言,當研究人員使用自迴歸模型預測下一個週期的收益率時,雖然自迴歸的具體迴歸係數會在逐次優化中不斷地被估計出來,但是自迴歸的階數設置往往會被研究人員在整個推進分析中固定爲一個常數。這種固定階數的做法對於推進分析的某次操作本身是沒有任何影響的,但是問題在於,如果一個研究人員在試驗了階數爲5的自迴歸擇時策略,發現其推進分析的結果沒有顯著盈利能力之後,又試驗了階數爲6、7、8、9、10的自迴歸擇時策略,最後發現9階自迴歸模型構建的擇時策略具有一定的盈利能力, 並將其確定爲實盤使用的交易策略,就會產生過度擬合檢驗不完全的情況。在這個例子中,階數實際上可以被看作策略的一個具體參數,對不同階數的自迴歸策略都進行測試並選擇結果最優的一種, 也就可以被視爲一次最優化的過程。但是直到決定使用9階自迴歸策略進行實盤操作爲止,研究者都沒有針對這一參數分析其過度擬合的情況。
在大多數模型優化方式比較固定的情況下,這種模型設置類的參數都是難以和模型係數-起進行優化的, 因而常常會被研究人員在推進分析中設置爲某一固定值。例如在上面所舉的例子中,自迴歸模型的迴歸係數估計一般都會使用普通最小二乘法等計量經濟學中常用的估計方法來完成,這些方法本身是不能用來同時優化自迴歸模型的階數設置的。更爲明顯一些的例子,是採用諸如人工神經網絡這樣的機器學習算法進行構建的量化交易策略,這些算法的擬合技巧往往都較爲複雜,而且在長時間的科學研究過程中會固化出一些公認的有效處理方法,甚至包括諸如模型預訓練這樣的複雜操作。不易變動。因此在絕大多數情況下,試圖更改這些擬合方法進而同時優化人工神經網絡隱層節點數之類的參數都是不切實際的。其他一些情況包括支持向量機中的核函數選擇等,雖然不再是一個直接的參數,但是仍然能夠通過人爲控制來改變整個策略的實際效能,因此嘗試多種核函數的做法同樣等同於最優化的過程。或者更爲隱敝的訓練樣本大小,也應該被看作一種參數,只不過這種參數來自對推進分析本身的設置。以圖6-2所展示的推進分析爲例,如果研究者分別在白色框長度爲3、4, 5、6.7等設定的推進分析框架下測試了同一種量化交易策略,最後發現長度爲5時策略收益最高,並在實際運行中也將優化期固定爲5個週期,那麼就同樣缺乏對於白色框長度這一設置的過度似合程度判斷。
這一節中將要介紹的多層推進分析,正是爲了緩解這一問題而針對推進分析流程進行的改進。多層推進分析的原理敘述起來較爲簡單,就是在推進分析的基礎之上,針對進行交易的灰色框序列再做新的推進分析,從而研究上一層推進分析中無法檢驗的參數過度擬合情況。但是實際上,在量化交易策略研究中,多層推進分析的邏輯其實較爲複雜,如果不小心處理就有可能會出現細節上的錯誤。在研究人員較難駕馭這種複雜邏輯的情況下,作者建議最好避免使用這種方法,爲了測試一些參數的過度擬合程度而導致整個回溯測試結果的不可信,其實是得不償失的。當然,接下來依然要介紹這種方法的具體操作流程,讀者可以在量化交易策略的研發過程中基現實情況來判斷使用與否。
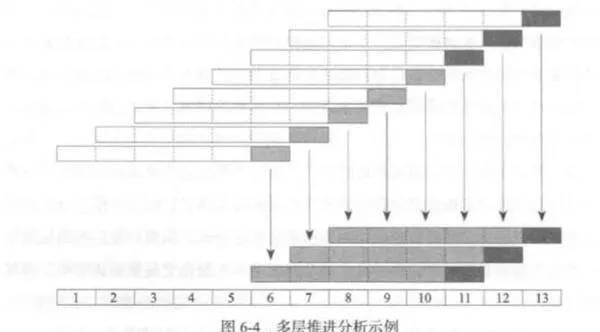
圖6-4在圖6-2所展示的推進分析的基礎上,給出了一個兩層推進分析的示例用以說明。在圖6-2中,每一個灰色框都是所在行的樣本外數據,而在圖6-4中,一部分的灰色框除了作爲第一層推進分析的樣本外數據以外,同時還是第二層推進分析的樣本內數據,用以優化在第一層推進分析中無法同時優化的參數。以第二層推進分析中的第-行爲例, 在第二層參數固定爲某定值的情況下,如同圖6-2中所做的-樣,基於週期1到週期5的數據進行優化得出一個最優策略,應用在週期6的數據上就可以得到該交易策略在週期6的收益率,同理,週期7可以根據週期2到週期6的數據優化出一個最優策略並得到相應的收益率,依此類推直到週期10爲止。綜合週期6到週期10的收益率結果,就可以得到第二層參數設爲該定值時這5個週期上的策略收益情況,之後更換第二層參數的設置,重複上述過程,得到其他參數情況下的策略收益率。在獲得第二層參數所有可能取值下的策略收益率後,就可以選出收益情況最好的一個或一組參數,這一輪操作可以看作是第二層推進分析中的樣本內優化過程,如圖6-4中的淺灰色部分所示。
在得到第二層參數的優化值之後,將策略中相應的設置固定爲該優化值,然後回到第一層推進分析當中,基於週期6到週期10的數據,對第一層推進分析的參數進行優化並得到優化結果。這樣,針對週期11而言,使用前期數據同時得到了最優的第一層參數值和第層參數值,將基於這此參數設置的策略應用到週期11的數據之上,就可以得到一個兩層推進分析的樣本外交易結果,如圖6-4中的深灰色框所示。至此,針對第二層推進分析中第一行的操作全部完成。
然後將所有的時間窗向後推進一個週期進行同樣的工作,可以完成第二行的操作。通過不斷地向後推進一個週期直到整個數據樣本結束,就可以得到多行的第二層推進分析結果,當然圖6-4受空間所限只展示了三行。將深灰色框下最優策略的模擬交易結果進行綜合,就可以得到該量化交易策略在兩層推進分析下的策略淨值走勢和收益情況,從而判新出第二層參數的過度擬合程度,並更好地對整個策略的真實盈利能力加以判斷。
上面介紹的是雙層推進分析的具體流程,在第二層推進分析的基礎之上,可以採用相似的方法進一步劃分數據,進而形成第三層的推進分析。只要數據量足以應對複雜化的推進分析過程,這樣的分層就可以持續地進行下去。但是需要注意的是,多層推進分析雖然可以解決一層 推進分析無法完全解決的參數優化與過度擬合判斷的問題,但是同時會引入新的參數設置,增加整個研發流程的複雜程度。
舉例而言,當一層的推進分析已經可以在樣本內優化所有的策略參數和設置時,這個時候需要固定的參數只有推進分析本身的訓練樣本大小,即圖6-2中的白色框長度。此時如果使用雙層推進分析來判斷訓練樣本量的設置是否存在過度擬合問題,那麼檢驗的也只是第一層推進分析中的訓練樣本量參數,而第二層推進分析又會引入一個新的訓練樣本量設置,即圖6-4中的淺灰色框長度,同時優化白色框長度時的取值範圍也是一個新引入的設置,這些參數、設置依然是人爲設定的,並有可能存在未來信息和過度擬合的雙重問題。這樣看來,不管多加多少層的推進分析,人爲設置的參數總是存在的,多層推進分析不能從根本上解決這個問題。
不過即使是在這種情況下,多層推進分析的引入依然是有一定作用的。在交易資產特性、市場環境緩慢變化的前提假設下,多層推進分析中更高層的設定參數應該比低層的參數變化更加穩定,因此增加推進分析層數並對上一層推進分析的設置進行過度擬合判斷是一個相對而言更爲穩定、可信性更高的回溯測試流程。
但是與此同時,由於多層推進分析提高了整個回溯測試的複雜程度,因此也同時提高了對樣本數據量的需求,層數越多,需要的樣本數據就越多。而遺憾的是,中國的金融市場與資本市場由於歷史較短,因此歷史數據量相對而言是較少的,同時市場環境、政策法規的頻繁變化使得可用的樣本數據更爲有限,在本書主要討論的中低頻量化交易策略的背景下,多層推進分析往往缺乏實際的使用基礎。
因此,本節所介紹的方法雖然有其意義所在,但是實際使用需要結合具體情況認真分析,作者自已在應用時也會相當的謹慎。本節內容更重要的意義,其實是更進一步地挖掘推進分析框架的內涵、特性及其與現實交易環境的關聯性,促使讀者深入地理解推進分析。