
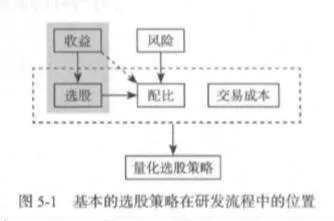
在上一章中,作者介紹了最基本的擇時策略以及簡單的一次性優化過程。作爲與擇時策略同樣重要的選股策略,其在橫截面上的作用與擇時策略在時間軸上的作用是量化交易策略的兩個重要方向。在這一章中,作者就向讀者介紹最基本的量化選股策略是如何構建起來的,同時引入一些相應的實際案例用以說明。與上一章一樣,這裏所謂的最基本的選股策略,指的也是隻判斷買賣、不涉及倉位優化的選股策略,或者更貼切地說,是在挑選了合適的股票之後,只簡單分配資金、不做具體配比優化的選股策略。圖5-1通過灰色區域說明了基本的選股策略在研發流程中所處的位置。由於不考慮風險的問題,因此選股策略完全是通過判斷收益情況來挑選股票的。同樣的,爲了給讀者提供較爲清晰易懂的量化選股策略以供入門,因此會在策略的優化過程中使用全樣本數據進行簡單的優化,進而產生出未來信息的問題。不過對於單因子選股策略和多因子選股策略而言,未來信息問題的表現情況不盡相同,在後面的內容中會具體說明。
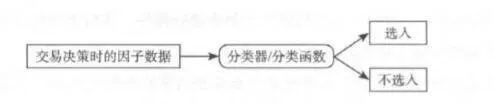
單因子選股是整個因子選股策略框架的基礎。一方面,單因子選股可以直接反映該因子的獲利能力,如果單因子選股策略的收益情況達到要求,是可以直接用來進行策略交易的;另一方面,單因子選股的過程實際上與因子挑選密切相關,在大多數情況下,只有在單因子選股過程中能獲得一定收益的因子, 纔有理由被納人多因子選股策略的考量之中。其實相較於多因子選股策略的模型,單因子選股策略非常的簡單直接,圖5-2給出了一個最爲粗略的單因子選股策略框架,在決定選股的時間點上,通過分類器來判斷因子的取值是否符合一定條件,如果符合則將股票選入,在下一期持有。
在這樣的框架下,選股策略在表面上並沒有涉及對後一期股票收益的預測,也沒有使用一般意義 下的最優化手段。不過就作者的看法,預測在分類時已經暗含其中,測試不同因子的過程也可以被看作在實踐中,因子選股已經是一個相對成熟而且大致框架較爲固定的策略,同時存在一個業界從業人員都較爲認同的策略體系,本書作爲一個以介紹策略框架爲主要目標的作品,也無意去變動或複雜化這樣一個體系框架, 因此在內容上基本介紹最簡單、最受認可的策略構建方法。而操作單因子選股策略時,需要考慮到將單個因子融合進多因子策略的問題,因此在分類.判別的部分不宜過於複雜,甚至可以說存在一個較爲固定的判別模式。簡單而言,就是在交易決策時按照當前因子影響力的大小進行排序,然後選人排序前列的股票,排序選擇順序還是逆序則由下一期收益率與因子的具體關係決定,最後保證選取股票的收益率相對更高即可。圖5-3給出了這樣一個基本的單因子選股策略框架。
多因子選股策略方面,本書也選用一個較爲成熟的策略框架來進行介紹。首先假定已經選出了N個有效因子,分別用看到龍標記,然後針對每一隻股票,用這N個因子的值來預測下一期或者下一段時間的收益率。這裏選用簡單的線性迴歸來完成預測工作,如下式所示:
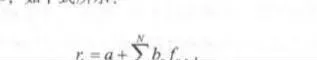
式中,r,是時刻1的股票收益率; fun.r-1是1-1 時刻下第n個因子的大小; a和b。是迴歸式中的係數。
進行交易決策的時間點爲1時刻初、1-1 時刻末,因此迴歸式左邊爲預測值,迴歸式右邊的所有成分則都是決策點下的已知信息。在預測出每一隻股票在時刻↑的收益率之後,按照收益預期值從大到小進行排序,然後選取排在前列的股票作爲當前可以建倉的股票。

需要特別說明的是,在某些量化交易策略的相關資料當中,會把對於不同股票而言取值一致的迴歸係數b,稱爲風險因子,而將具體的股票特徵值f -稱爲各只股票在因子上的溢價。這主要是因爲學術界在套利定價理論等研究的基礎上,形成了一種約定俗成的叫法,其中風險因子對於所有資產應該保持一致,面因子溢價則各有不同。不過在量化選股策略中,對比本節所使用的稱謂,這種叫法以及其他一些叫法並不是非常直觀,因此不予以使用。如果讀者在閱讀其他資料時碰到不一樣的名稱,只需對號入座弄清準確含義即可。a和b,等參數的優化和擬合,書中使用的是法瑪等人給出的一種線性迴歸估計方法。如果可以獲得T個時間段的因子數據以及相應的下-期股票收益率數據,那麼對於上面的線性迴歸式而言,一共可以進行T次估計,表示如下:
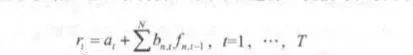
相比起上一個迴歸式,a和bn的形式略有變動。ar 和bn, ,代表一共可以得到T組a和b,的參數估計值。然後將T個a,求平均值,就是參數a的擬合結果;分別將T個bn, ,求平均,則得到N個bn各自的擬合結果。

圖5-4展示了基本的多因子選股策略的基本框架,和單因子選股策略不同的地方在於,單因子選股直接針對因子進行排序來選擇股票,而多因子選股需要先基於因子預測股票的未來收益,然後對預期收益進行排序進而選擇下一期持有的股票。因此,多因子選股策略中很明確地包含了預測的成分,以及通過估計迴歸模型來完成的最優化手段。如果像第4章一樣僅介紹簡單的選股策略,那麼從表面上來看,多因子選股策略的研究過程中由於存在迴歸模型的.一次性估計,因此包含未來信息的成分,而單因子選股策略的研究過程中則不存在未來信息的問題。但是正如前面所言,不斷地嘗試不同的因子、最後挑選出合適因子的過程.
實際上也是在進行最優化的篩選,這其中暗含的未來信息問題,需要研究人員加以注意。
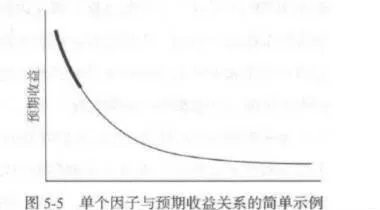
在本節開始處作者提到過,單因子選股模型一方面可以直接反映該因子的獲利能力,另一方面可以過渡到多因子選股策略的準備工作因子挑選之上。不過單因子選股模型在這兩個方面發揮作用的時候,策略研發人員的關注點和需要處理的細節問題都有細微的差別,圖5-5給出了一個簡單的例子用來說明。當研究人員使用單因子模型直接構建交易策略進行交易時,主要關注的是被選人股票的收益情況,如圖中曲線的加粗部分所示。只要這-部分的未來收益能夠達到標準即可,至於因子大小排序在後面的股票,不管是展現出如圖中的非線性趨勢,還是有明確的線性趨勢甚至是沒有一個顯著的走勢,在重要性上要遠遜於選入股票的收益情況,至多影響到策略的進一步改進。但是當研究人員使用單因子模型來挑選有效因f從而構建多因子模型時,由於涉及具體的收益預測問題,單個因子在多因子預測中需要合併起來使用,因此整個曲線的性狀都是要加以考慮的問題。而本書中所述的多因子策略方法基於線生迴歸模型,因此預期收益和因子大小之間符合線性關係是最優狀態,當1兩者的關係呈現出如圖5-5中所示的非線性關係時,在線性迴歸步驟之前對因子或收益數據做合適的預處理,例如法瑪所使用過的對數化,就是個很有必要的過程。